
Core AI for PMs: Generative AI Product Glossary I
Understand generative AI concepts and lead AI product discussions

Understanding core generative AI concepts and terminology is one of the key elements to enable effective communication between product, research, data science and engineering teams.
In this post, we define:
Generative AI Key Terminology
Generative AI Flywheel
Generative AI Key Terminology
Large Language Models (LLMs)
Multi-modal LLMs have the ability to ingest multiple inputs (text, images, audio, code) and produce outputs that model the human brain in terms of knowledge generation and reasoning. You can refer to the previous post for a comprehensive analysis of multiple types of multi-modal LLMs.
LLMs predict the next word based on training examples that were collected on the internet. These training examples are passages of text from a variety of sources. To help the model learn, we hide words from the passage and ask the LLM to learn how to discover the hidden word.

The output of an LLM model is a probability distribution of the next word as shown in the graphic below.

Token
We cannot feed LLMs with a large text input at once. Instead, we parse it by breaking it down to smaller “chunks”. Those chunks are words, subwords or multiple words. The process of breaking down text into tokens is called tokenization.

Embeddings
While humans understand words or tokens, LLMs understand numbers. The first step in LLM processing is to convert each token into a numerical representation called an embedding. You can think of embeddings as the vocabulary of LLMs. There are multiple types of embeddings depending on the use case. We can compare words by quantifying how close their embeddings are.

Attention mechanism
The attention mechanism enables transformers to have long term memory, so that they can attend or focus on all previous tokens that have been generated. This mechanism was inspired by the human vision system, where our eye sensory system can help us pay attention to a fraction of the visual information we receive.
Transformer
A transformer is a type of deep learning model. It is the building block of LLMs, originally introduced by Google researchers in 2017 in the paper “Attention is all you need”.
The general strategy to improve a transformer’s performance is to increase the size of the model, the time spent training it and the amount of pre-training data. However, these have implications such as increased computational cost and negative environmental impact. For example, HuggingFace estimated that on average training a state-of-the-art LLM model (~200B parameters) is equivalent to ~84 roundtrip NY-SF flights in terms of CO2 emissions.

As product leaders, we need to ensure alignment not only on business strategy but also on the company’s sustainability strategy. Some aspects to consider for achieving alignment between product and sustainability teams are:
use hardware efficiently (e.g., GPU utilization), training time
utilize pre-trained models when available
fine-tune instead of training from scratch
These strategies can help reduce the carbon footprint of LLMs.
Interesting resources for calculating the emissions of LLM training are:
ML emissions calculator based on hardware type used
Generative Pre-trained Transformers (GPT)
GPT is a type of LLM developed by OpenAI. This model and its subsequent versions have been trained with billions of parameters, which incurs massive training costs.

Fine-tuning
Fine-tuning is a process for training a pre-trained model on a new dataset to improve its performance on a new task. It’s commonly used as it requires much fewer computational resources compared to training a model from scratch.
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning with Human Feedback (RLHF) is an AI technique that is central for LLM alignment. RLHF uses direct human feedback to train the model.
In conventional Reinforcement Learning (RL), an agent learns to make decisions by engaging with its environment and getting rewards or punishments for its actions. With RLHF, the environment consists of real humans. Humans can offer detailed and subtle feedback, assisting the AI model in grasping not only the task's procedures but also its core values and goals. This human input can come in the form of direct guidelines, adjustments, or by comparing various model results to determine the best one.
RLHF involves humans ranking language model outputs sampled for a given input, using these rankings to learn a reward model of human preferences, and then using this as a reward signal to fine-tune the language model with RL.
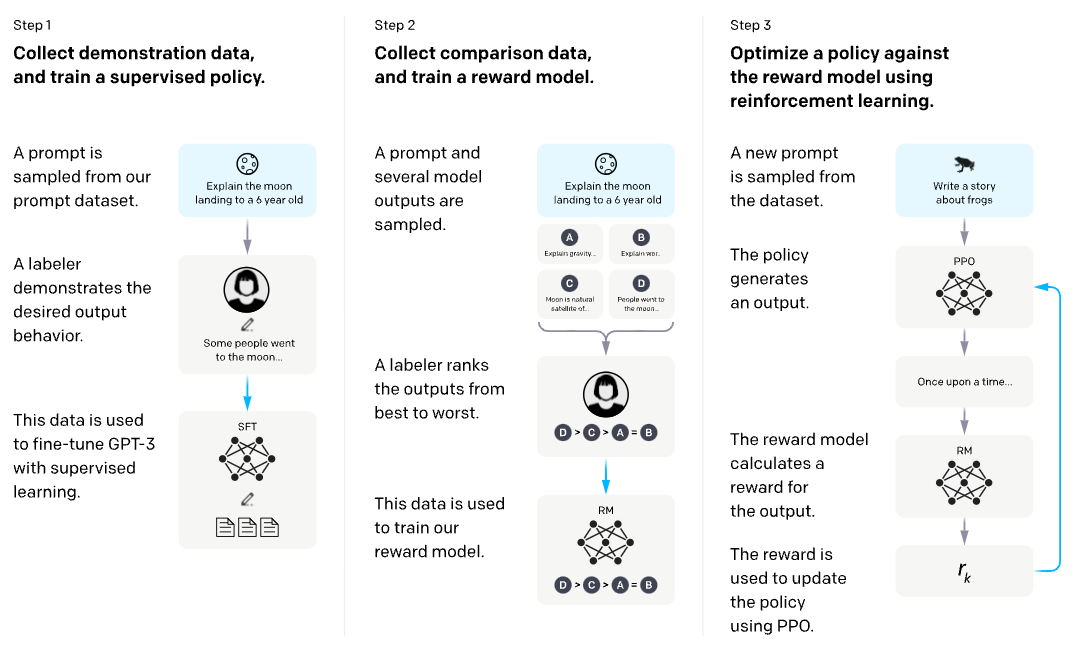
Here are some challenges associated with RLHF that we need to consider as PMs:
🔹 Quality of human feedback: Inconsistent or biased feedback can lead to suboptimal or even incorrect model behaviors.
⚖️ Scalability: Obtaining human feedback for every possible scenario can become challenging, expensive and time-consuming. In some cases, specialized expertise may be required.
❓ Ambiguity: Multiple human evaluators might have different opinions on what the correct action or output should be.
⏲️ Temporal consistency: Societal norms and values may change and feedback may become outdated.
🦺 Safety concerns: Incorrect feedback or misinterpretation of feedback may lead to unsafe behaviors by the AI agent.
✳️ Overfitting to feedback: There is a risk that the model may perform well on the feedback data but poorly in real-world, unseen scenarios.
🔥 Ethical concerns: Deciding who should provide feedback and whose values the model should align with may raise ethical concerns.
Food for thought:
👉 How can we effectively measure the trade-offs of RLHF tuning against human labor?
👉 What are the social and economic equity implications when selecting human subjects for RLHF?
👉 Who should govern RLHF policies and evaluate the results?
If you’re interested in learning more, here’s a comprehensive paper: https://arxiv.org/pdf/2307.15217.pdf
Hallucination
LLM models do not often say “I don’t know”. As as result, they will often produce answers with inaccurate or fictitious information.
For example, if you ask an LLM a question like “who was the tech vp that had 12 children” the LLM might provide a detailed and imaginative answer:
As of my last training cut-off in January 2022, the most notable tech VP known to have had 12 children is R— K—. R— K— is an American inventor, futurist, and director of engineering at Google. However, it should be noted that he did not actually have 12 children. This might have been a confusion or misinformation.
This is a form of hallucination because the LLM created a fictitious scenario that is not based on reality. This is why it is critical for product managers to set guardrail metrics to prevent generative AI systems from providing inaccurate and unreliable information.

Generative AI Flywheel
After defining the first part of generative AI core terminology, it is important to link all concepts into a comprehensive set of product requirements and AI product roadmap. This is why I created the generative AI Flywheel. It is composed of 3 pillars: data, AI models and user feedback, each of which plays a crucial role in the generative AI product development lifecycle.

In short, these 3 pillars closely interact and influence each other. For example, better data means better algorithmic outputs and better user interaction/feedback, which then can be fed with RLHF (or other) techniques to further improve the generative AI Flywheel. As you can see, this is an iterative process and it is expected to get better and better over time. Let’s break down its key components.
The key data components are:
👌 Quality: AI models need vast amounts of data for training purposes. Identifying data collection strategies, sources, high-quality data requirements and data providers is an essential step.
#️⃣ Quantity: When it comes to the right amount of data vs quality tradeoff, this is an ongoing research area. For more context, you can check the neural scaling laws and how LLM performance improves predictably when increasing the dataset size, model parameters and amount of compute used: https://arxiv.org/pdf/2001.08361.pdf
🦺 Safety/Privacy: There are a lot of safety considerations, one of the primary ones being watermarking AI-generated content. Recently, the White House announced that the Department of Commerce will develop guidance for watermarking (Source: White House). This is an ongoing research field, you can read more in our previous post.
The key algorithmic components are:
⛓️ AI value chain: It is critical to define foundational model builders, MLOps and infrastructure pipelines or providers, hardware and application requirements and success metrics.
💡 Interpretability: The ability to interpret model predictions is vital for trust, debugging, fairness assessment with the goal for the algorithms to be human understandable.
👀 Observability: It is important to understand at which stage of product development we are, in order to implement the right LLM observability strategy (early stage/MVP, production evaluation, post-launch evaluation). We will explore these strategies on a separate post.
The key user feedback components are:
👥 UX: User feedback can have various formats: prompt submission, instruction tuning or feedback on the outputs of LLMs. It is important to define strategies on using that feedback to improve LLM performance (e.g., RLHF). All other elements of user engagement, satisfaction and UX experience are important on AI products that involve a user interface.
⚖️ Ethics: Legal and ethical considerations are key when developing AI products. Especially, when it comes to sensitive data and human subjects, leveraging the guidelines of the Belmont Report is a great start towards defining ethical data strategies.
🔒 Privacy: This is a dynamically changing area as new requirements are going to emerge based on new legislation similar to the EU AI Act and the recently announced White House Executive Order on Safe, Secure and Trustworthy AI.
In the next post, we will present the Generative AI Product Glossary II, where we focus on LLM evaluation processes and other LLM performance improvement strategies such as Retrieval-augmented generation (RAG)!