


Core AI: Multi-modal AI & applications
How multi-modal AI enables multiple new applications, market landscape & industry predictions

In the next posts, we’ll delve into Core AI topics starting with multi-modal AI:
what it is
current market landscape
main applications
industry adoption predictions
Multi-modal AI
Foundation models (the core models behind AI development) can ingest the following inputs/outputs:
📝 Text
🖼️ Image
</> Code
🎥 Video
🎵 Sound
💬 Speech
📦 3D
🤖 Robot state
Multi-modal AI models can accept as input or output multiple data modalities other than text (e.g., images or video).
Common combinations are:
📝 + 🖼️ → 📝 : Multi-modal LLMs
📝 + 🖼️ + 🤖 → 📝 : Multi-modal LLMs for robotics
📝 → </> : Text to Code
📝 → 🖼️ : Text to Image
📝 → 🎥 : Text to Video
📝 → 🎵 : Text to Sound
📝 → 💬 : Text to Speech
🖼️ → 📦 : Image to 3D
📝 → 📦 : Text to 3D
Current market landscape & trends
The “better, faster, cheaper” wave opens the floodgates for application development and multi-modal AI plays a crucial role in expanding the use cases and applications. In fact, recent studies have shown that technology can achieve human-level performance in some capabilities 40 years faster than previously expected (Sources: McKinsey & Company, Sequoia Capital).


Let's break down each foundation model, its main applications and inputs/outputs. Some applications below have a lot of potential for improvement and are tagged with [research phase].
Main applications
📝 → 📝: Large Language Models
Commonly, Large Language Models (LLMs) have been used to write content, as chatbots or assistants, simplifying search and for analysis or synthesis. The main data modality for LLMs is text.
📝+ 🖼️ → 📝 : Multi-modal LLMs
Latest LLMs such as GPT-4 are multi-modal AI models outperforming its predecessors especially in reasoning capabilities.


LINGO-1 is a multi-modal AI model that provides information about the driver’s behavior or the driving scene as commentary.


📝+ 🖼️+ 🤖 → 📝 : Multi-modal LLMs for robotics [research phase]
PaLM-E is a foundation model trained on images, text and robotic state data. It can control a robotic arm in real time.

📝 → 🎵 : Text to Sound [research phase]
New models from Google, Meta and the open source community significantly advance the quality of controllable music generation.
MusicLM (Google), samples: https://google-research.github.io/seanet/musiclm/examples/
MusicGen (Meta), samples: https://ai.honu.io/papers/musicgen/
AudioCraft open source models include MusicGen (music generation from user prompts), AudioGen (sound generation from user prompts) and EnCodec (audio compression for reduced artifacts)

Generative AI tools for sound and music (Source: Meta)

📝 → 🖼️ : Text to Image
Lots of applications here and many commercially available models like Dall-E 3 (multi-modal AI model) and the Imagen model family. These models are already integrated in multiple products such as Imagen’s integration in Google Cloud Vertex AI, Google Slides and Dall-E-3’s integration with ChatGPT-Plus and enterprise customers.

This year, we have seen new methods enabling co-pilot style capability for image generation and editing such as products by Genmo AI that enable a co-pilot style interface for image generation with text-guided semantic editing.
📝 → 🎥 : Text to Video [research phase]
The race in text to video model development continues with high resolution video generation (up to 1280 x 2048!) by NVIDIA.

Other text to video foundation models are Phenaki (by Google) and Make-a-Video (by Meta).
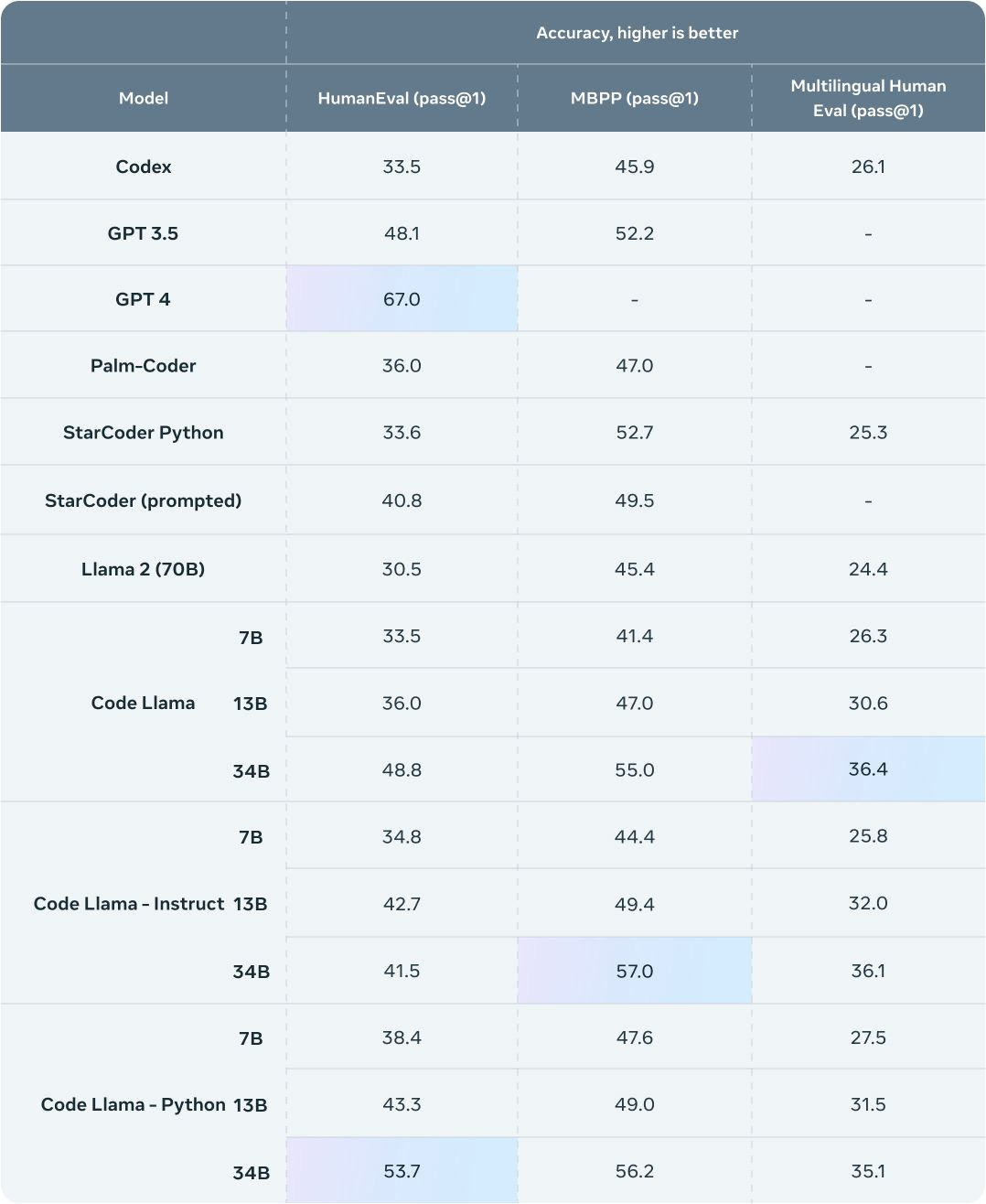
📝 → </> : Text to Code
GPT-4 Code Interpreter is the leading foundation model. Some text to code use cases include generating code from text prompts, completing code, and even debugging.
There are some other research developments and recently open-sourced models such as Code Llama that showcase superior performance compared to GPT-4 when tested in specific benchmark datasets.
📝 → 💬 : Text to Speech [research phase]
SeamlessM4T is a multi-modal AI model used for translation and transcription. The model supports nearly 100 languages for input (speech + text), 100 languages for text output and 35 languages (plus English) for speech output. However, it is only available for non-commercial use.

📝 → 📦 : Text to 3D [research phase]
3D is a particularly challenging domain for generative AI models. Compared to image or even video, 3D datasets are rarely available. Additionally, 3D generation not only includes shape, but also other aspects such as texture or orientation, which are hard to capture in text representation. Therefore, use cases for image to 3D and text to 3D are in research stages.
An example is Shap-E (by OpenAI) that can generate photorealistic and highly detailed 3D objects directly from short written descriptions.

There is significant potential with further development of these models especially for gaming and AR/VR use cases.
Industry adoption predictions
The recent and ongoing foundation model developments enable an array of opportunities in multiple industries and business functions. According to a recent study by McKinsey & Company, high tech and banking will have the most significant impact, while marketing and sales, customer operations and product/R&D will be impacted the most compared to other functions.
Adoption rates will vary depending on the scale of an industry’s revenue, agility in software development and personnel training/AI skills’ development, to name a few.
Given the rapid developments of AI models, we would need to closely observe new developments to all stay-up-to-date on the recent advances and highest ROI to bring those to market.

