
Designing Data Pipelines: A Deep Dive into Efficient Data Annotation


We are pleased to continue our article series on Data Labeling for Product Managers with our contributor José Luis Muñoz !

TLDR
Today, I want to unpack a topic that's crucial yet often overlooked in the realm of AI and machine learning - designing effective pipelines for data annotation. If you're a Product Manager, especially in a cutting-edge field like robotics delivery, this article is tailored for you. But even if you're just curious about the mechanics that power these revolutionary technologies, stick around - there's plenty to learn!
Concepts Covered
Setting the Scene: The Challenge at Hand
Zooming In: Focused Factory Approach
A Glimpse from My Early Career: Lessons from Imagery Analysis
Designing Tasks to Reduce Variation
Comparing Approaches: Single vs Multiple Pipelines
Double Click - Further Subsetting
Conclusion
Setting the Scene: The Challenge at Hand

Let's assume you are a Product Manager at a robotics delivery firm (e.g - Tiny Mile). Your mission? To spearhead the development of a state-of-the-art Computer Vision object detection model. The task seems straightforward: your ML Perception team needs the model to excel in three key areas:
(1) human pose estimation,
(2) traffic sign detection, and
(3) traffic light detection.
At a glance, it might seem like a straightforward project with just three clear requirements. However, if you delve a little deeper, you'll uncover layers of complexity. Each of these three requirements comes with its unique set of attributes, weaving a web of intricacies. With the extensive combined taxonomy of these classes, the real challenge emerges: as a Product Manager, how do you streamline and simplify the data labeling process to meet these sophisticated requirements efficiently? This is where your strategic thinking and innovative approach come into play. Let's explore how you can navigate this complexity and lead your team to success.
Zooming In: Focused Factory Approach
In the first article in our series of Data Labeling for PMs, we explored the power of specialization through the lens of Shouldice Hospital’s remarkable success in focusing solely on hernia surgery. This principle of a focused operations strategy is not just limited to healthcare; it’s equally applicable to data pipelines.
Bottom line takeaway - When you narrow the range of tasks within a data pipeline, you effectively minimize variability. This reduction in variability is more than just streamlining; it's about creating efficiency. Imagine a less congested queue where each task is handled with precision and speed - that's the power of specialization in action.
Let’s put it in another way. - By honing the scope of annotation tasks, we, as Product Managers, can architect data pipelines that are not just faster, but smarter. It brings to mind the old wisdom, “A jack of all trades is a master of none”. In the context of data pipelines, mastering a specific set of tasks leads to quicker processing times and, ultimately, a more robust and efficient system. This focused approach is the key to unlocking greater productivity and effectiveness in your projects.

A Glimpse from My Early Career: Lessons from Imagery Analysis
I began my career in the United States Air Force as an Imagery Intelligence Analyst. Imagery Analysts are colloquially referred to as “squints” due to the fact that they review multispectral remotely sensed data to derive intelligence insights.
In this realm, specialization isn’t just a practice; it’s a necessity. From my experience, each imagery analyst becomes a connoisseur of a specific geography or a particular phenomena in order to become a subject matter expert. For example, imagine one analyst immersed in the nuances of North Korean submarines, while another is an specialized on Russian Intercontinental Ballistic Missiles. This deep dive into specialized areas transforms analysts into subject matter experts.
The same specialization of imagery analysis expertise can be applied to computer vision data labeling. The requirements are as distinct as they are critical - ranging from Lidar annotations to 2D image markings. Just as it would be counterproductive for an analyst to analyze both North Korean submarines and Russian missiles, expecting a data labeler to master disparate annotation types simultaneously is far from optimal. Specialization ensures precision and efficiency, whether in military intelligence or in the intricate world of computer vision.
Designing Tasks to Reduce Variation
Rather than designing a one-size-fits-all data pipeline, where annotators are tasked with simultaneously identifying human poses, traffic signs, and traffic lights, we need to apply a more effective approach. By segmenting these tasks into distinct, standardized pipelines, we enhance the focus and accuracy of our data annotation team. This specialized strategy not only streamlines the annotation process but also boosts the overall quality and efficiency of our data labeling efforts.

The above image illustrates a single frame of an annotation sequence. Keep in mind that a 30-second video at a frame rate of 10 hertz (frames/second) would result in 300 frames for a human to annotate! By creating dedicated data pipelines for each requirement of the perception team, we significantly narrow down the search area and reduce the cognitive load of our data annotators.
Tactical level considerations - Our annotation team, or 'data labelers,' work according to a set of precise annotation instructions. These guidelines are defined by the ML Perception Teams, and it's a delicate balance — the more detailed the requirements, the heavier the cognitive load on our annotators. Hence, simplifying and tailoring these instructions to suit each specific pipeline becomes crucial to maintain efficiency and accuracy in the annotation process.
Comparing Approaches: Single vs Multiple Pipelines
As a manager of mine used to say, “The best way to eat an elephant is one bite at a time.” This concept is best illustrated by the notional data pipeline images below.

The above image depicts a complex data pipeline where Lidar categorization, 3D Lidar annotation, and 2D annotation are conducted. The number of moving parts in this pipeline increases the complexity of operations. In contrast, the image below depicts a scenario, where these tasks are divided into three distinct data pipelines.
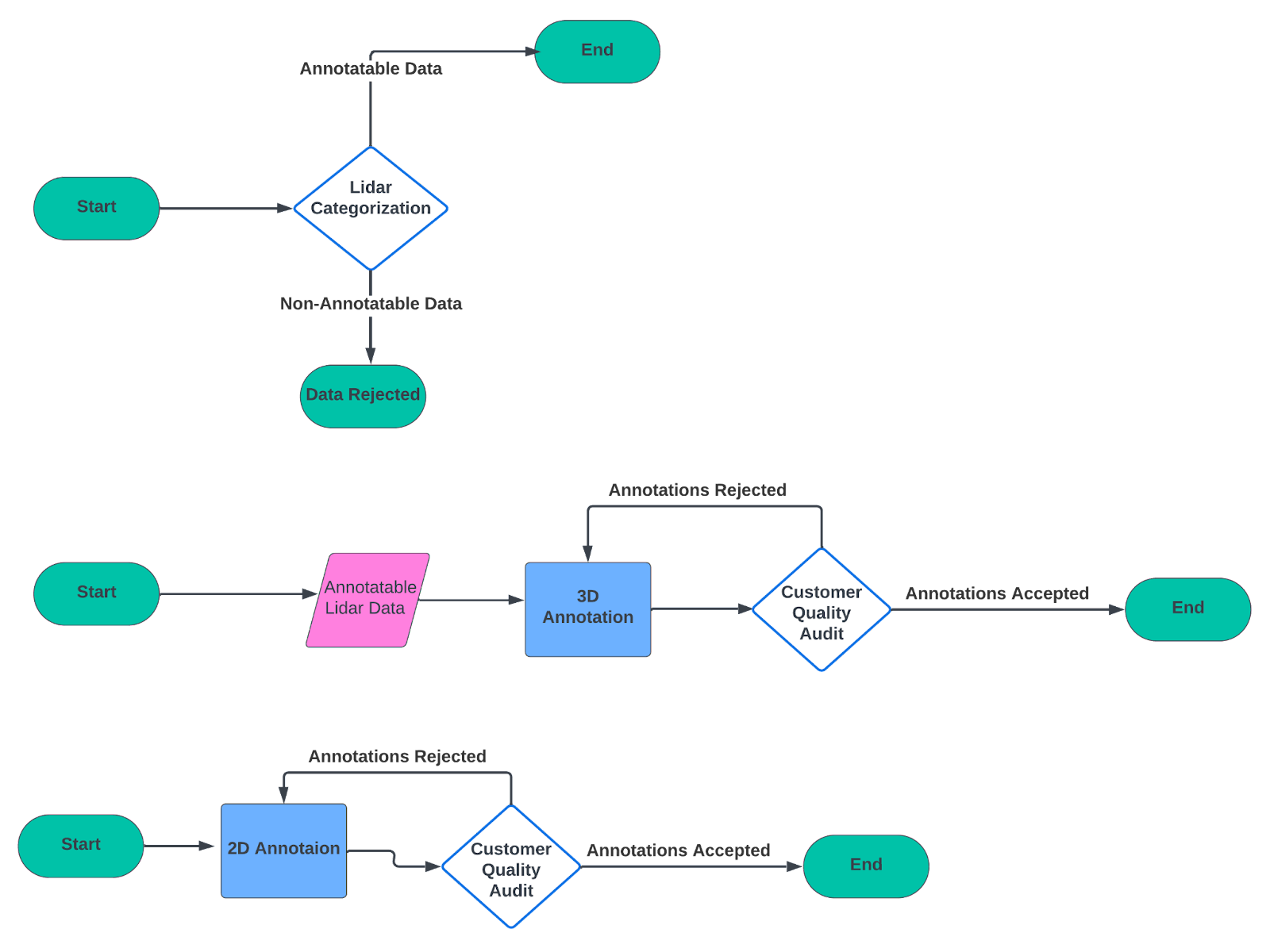
Key Process Improvement Highlights:
Faster feedback loops: By segregating tasks into individual pipelines, feedback becomes more targeted and rapid. This streamlined process ensures quicker turnaround times and more effective iterations, leading to a more agile development cycle.
Specialization of personnel: With each pipeline focused on a specific task, personnel can specialize in their respective areas. This specialization not only improves the quality of annotations but also enhances overall productivity and job satisfaction among annotators, as they become experts in their specific domain.
These enhancements underscore the value of specialized, focused pipelines in handling complex data annotation tasks, translating into improved efficiency, accuracy, and operational effectiveness.
Double Click - Further Subsetting
Revisiting our goal to develop a model adept at (1) human pose estimation, (2) traffic sign detection, and (3) traffic light detection, the strategic division of our data pipeline into three distinct streams becomes crucial. This separation allows us to tailor and enhance the specialization of our annotation team for each specific requirement, thereby minimizing operational friction and boosting efficiency.
The Product Process Matrix, as illustrated below, depicts the interplay between the structure of our processes and the nature of our product. In this context, our “product” refers to the data annotations meticulously tailored to meet the nuanced demands of our ML Perception team. Given this requirement for high-standard, specialized outputs, an assembly line process structure is best suited for our use case.
Why an assembly line? This approach enables us to compartmentalize and streamline each annotation task, much like a well-oiled machine where each component plays a distinct, crucial role. It ensures that the data annotations are not just consistent but are also crafted with a level of precision and quality that only a focused, assembly line process can achieve. In this setup, each segment of our pipeline acts like a station in an assembly line, dedicated to one of the three key tasks - ensuring our model's accuracy and reliability in human pose estimation, traffic sign detection, and traffic light detection.

At the tactical level, we can leverage a data curation tool (e.g., Voxel51 or Scale AI’s Data Engine) to curate scenes and then only serve the scenes of interest to specialized annotation personnel. The below process flow diagram depicts what a “focused” data pipeline might look like in this scenario. In this streamlined setup, each scene goes through a careful curation process where it's filtered and then directed to the appropriate team. This approach ensures that our annotators are only dealing with data that's directly relevant to their specialization, be it human pose estimation, traffic sign detection, or traffic light detection.
By leveraging these sophisticated curation tools, we not only optimize the workflow but also enhance the accuracy and efficiency of our data annotation efforts. This focused pipeline model embodies strategic efficiency, ensuring that each team member operates at their highest potential with the most relevant data at their disposal.

Conclusion

Once we look under the hood, there is a lot going on behind the scenes in data annotation. If the intricacies of data annotation are not for you, that is ok! In the words of the renowned management scholar Peter Drucker,
Do what you do the best and outsource the rest.
My experiences as a customer of data annotation services at Meta and as a provider of data annotation services at Scale AI have solidified my conviction in Druker’s management mantra. The good news is that there is a healthy market for data annotation services available, and not everyone needs to become an operations or data annotation expert.
In the realm of data annotation for something as cool as robotics delivery, it's all about getting specific and staying focused. Drawing from diverse fields like hospital efficiency and military intelligence, we learn that less is more when it comes to task variety in data pipelines. This strategy isn't just about keeping things simple; it's about supercharging efficiency, reducing wait times, and lowering the cognitive load of data annotators. So there you have it - staying laser-focused is the name of the game.

 | A guest post by
|